

Potęga tokenów, czyli o działaniu Sztucznej Inteligencji na poziomie komórkowym

Gdy oglądamy kolejne świetne zagrania w wykonaniu ulubionego piłkarza, zachwycamy się jego zwrotnością, szybką pracą nóg czy muskulaturą. Aby piłka wpadła do bramki, musi zagrać ze sobą wiele różnych zmiennych: od siły strzału, przez rotację piłki, po odrobinę szczęścia. Zapominamy jednak o tym, że kluczowa część tej pracy odbywa się na poziomie, jakiego nie jesteśmy w stanie dostrzec gołym okiem. Podobnie jest ze Sztuczną Inteligencją. Jaki jest jej najgłębszy poziom, jaki możemy przeanalizować?
Tokeny w SI: czym są i jak działają?
Aby dobrze uzmysłowić sobie, dlaczego tokeny są tak ważne, musimy cofnąć się w czasie o kilka lat. Pierwsze próby generowania tekstów bazowały na zasadach łączenia ze sobą słów. Algorytm próbował zrozumieć zachodzący między nimi związek przyczynowo skutkowy, a następnie, na podstawie wprowadzonych danych wejściowych, tworzył swoje własne publikacje.
Praktyka pokazała, że to rozwiązanie nie ma absolutnie żadnej racji bytu. Stopień złożoności wielu różnych języków, w tym polskiego, w zasadzie skazywał takie algorytmy na klęskę. Trzeba jednak usprawiedliwić twórców tych narzędzi — w czasach, kiedy pojawiały się pierwsze takie rozwiązania, moc obliczeniowa maszyn była o wiele mniejsza, niż ma to miejsce teraz.
Dopiero model przekształcający BERT, który został oficjalnie zapowiedziany pod koniec 2018 roku, zrewolucjonizował nasze myślenie o generowaniu tekstów przez Sztuczną Inteligencję. Firmowane przez Google rozwiązanie, które otrzymało odpowiednie zaplecze logistyczne, momentalnie zostało uznane za wzorzec, który zresztą (z pewnymi modyfikacjami) obowiązuje do dziś.
Głównym założeniem BERT-a była konwersja tekstu do wektorów liczbowych. Co to oznacza w praktyce? W pewnym uproszczeniu tekst zostaje rozbity do łańcucha znaków, które wykorzystuje dany model. W takich narzędziach, jak GPT-3, są to ciągi liter oraz cyfr.
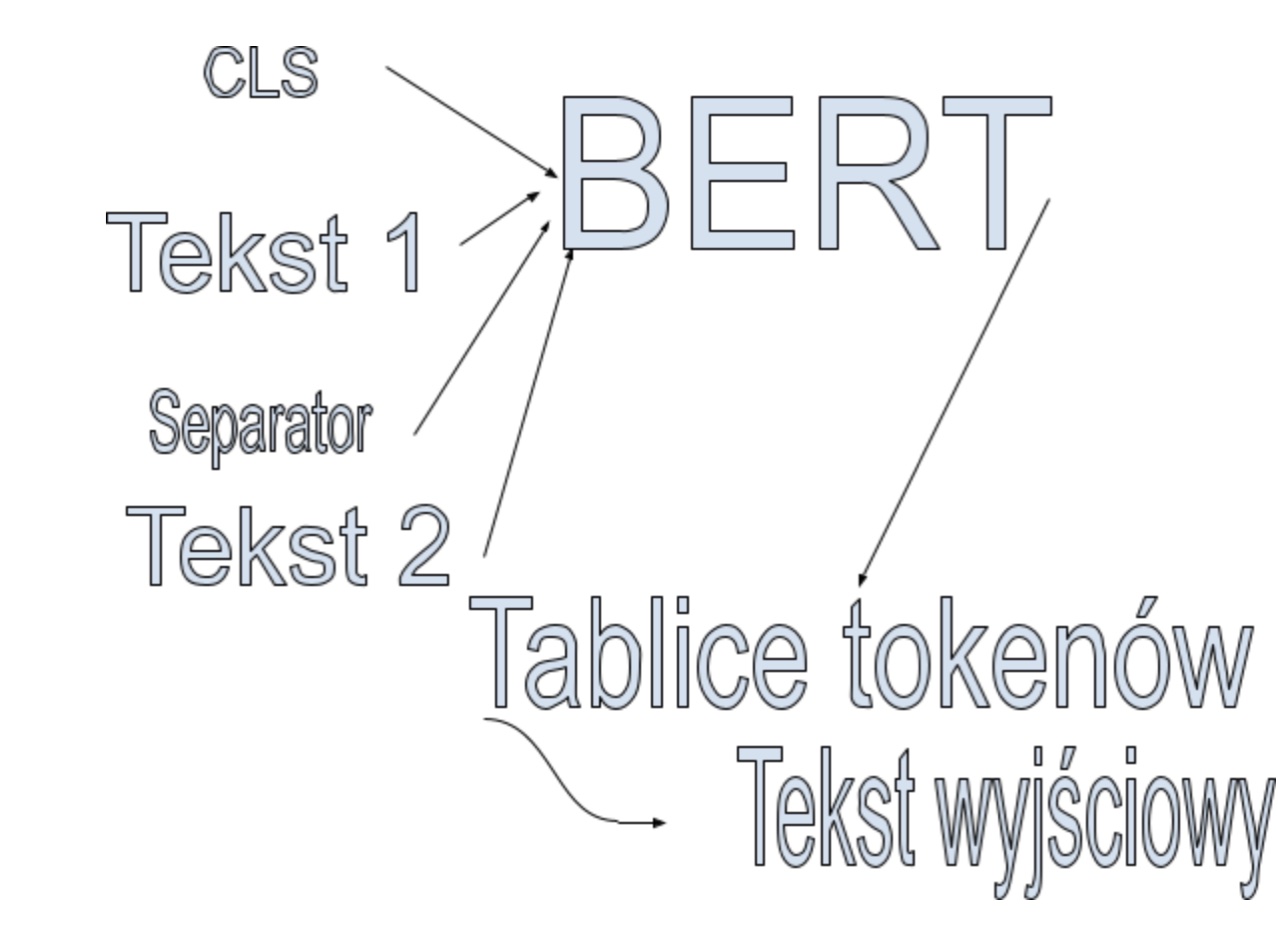
Wykres 1
Dużą rolę odgrywają tu tablice str, które wspiera Python. Dobrze można wytłumaczyć to na poniższym przykładzie, gdzie naszym zdaniem wyjściowym będzie: Takaoto to agencja SEO.
Pierwszym etapem pracy Sztucznej Inteligencji będzie rozbicie tego zdania na sylaby. Następnie, upraszczając nieco cały proces, zostają one powiązane z ciągiem liczbowym, jaki obsługuje dany model. Wybrana „sylaba” mogłaby wyglądać na przykład jako „#to13”. Właśnie w taki sposób SI może widzieć ”to” w zdaniu “Takaoto to agencja SEO”.
Dlaczego taki dodatkowy podział? Przecież w alfabecie łacińskim nie mamy setek liter, więc model powinien poradzić sobie ze zrozumieniem tekstu i zbudowaniem wokół niego pewnego kontekstu, prawda?
Programiści szybko zrozumieli, że tokeny bazujące na systemie znaków angażują o wiele więcej mocy obliczeniowej oraz czasu. Po stronie wad można też wskazać na bardzo dużą liczbę danych, potrzebnych do wytrenowania modelu.
W jaki sposób algorytm jest w stanie wygenerować mój tekst tak szybko?
Firmy, które oferują swoje usługi w formie webowej, szybko zrozumiały, że generowanie w taki sposób, jak opisany powyżej, treści, to zadanie niezwykle złożone i zasobożerne. A musi przecież istnieć o wiele lepszy sposób na wygenerowanie wpisu pt. „Jaką pralkę w 2022 roku kupić”, niż angażowanie potężnej mocy obliczeniowej serwera, prawda?
Branża znalazła odpowiedź na to pytanie, cofając się do korzeni. Już w modelu GPT-2, powrócił system tokenów, który (przynajmniej pośrednio) bazował na słowach. To rozwiązanie, które sprawdza się w przypadku języków, które są jednocześnie popularne w internecie oraz cechują się prostą składnią.
To właśnie dlatego teksty generowanie przez GPT-2 czy GPT-2 Large po angielsku, hiszpańsku czy francusku były o wiele bardziej logiczne i precyzyjne, aniżeli publikacje, które SI tworzy w języku polskim. Pewnego rodzaju „obejściem” tego problemu jest praktykowana metoda odrzucania rzadkich słów, które w większości modelów otrzymują token UNK (od: unknown — nieznany).
Przewidywanie tekstu w algorytmach nowej generacji
GPT-3 w dużej mierze spopularyzowało sztuczną inteligencję w Polsce. Coraz lepiej odnajduje się w branży SEO, ale i w codziennej pracy redakcyjnej. Nie brakuje tematów, gdzie publikacje wygenerowane w ten sposób oferują zaskakująco dobrą jakość już na etapie tworzenia tekstu, bez jakiejkolwiek edycji. Wciąż trudno tu jednak o powtarzalność. SI może nam dostarczyć zarówno świetny, jak i pozbawiony jakiejkolwiek logiki wpis.
W jaki sposób GPT-3 jest w stanie dostarczyć nam dobrej jakości treści? Kluczowy jest „wsad”, czyli odpowiednia liczba danych, dzięki którym model będzie w stanie przewidzieć szerszy kontekst danego zagadnienia. Dobrze ilustruje to poniższy przykład.
Naszym zdaniem wejściowym jest: Liverpool to najlepszy
Predykcja, czyli przewidywanie tekstu, które zapewne doskonale kojarzą wszyscy użytkownicy takich usług, jak Rytr i Jasper, określa liczbę predefiniowanych wyborów, jakich może dokonać model. Na potrzeby tego przykładu, załóżmy, że zgromadzone dane wskazują na:
– klub,
– stadion,
– obiekt,
– port.
Model wybierze to rozwiązanie, które pojawiło się najczęściej w sieci, czyli na etapie nauki. Załóżmy, że będzie to słowo „klub”. Co dalej? Teraz — na podstawie dokonanego wyboru — model już samodzielnie przewiduje kolejne kroki. Właśnie w tym miejscu doświadczamy Sztucznej Inteligencji w praktyce.
Model wytypował następujące typy:
– piłkarski,
– sportowy,
– nocny,
– taneczny.
Z tego grona najlepszym wyborem będzie oczywiście „piłkarski”. Co dalej?
– na,
– w,
– wśród,
– we.
To już nieco trudniejsze zagadnienie. Z jednej strony mogło pojawić się sporo odwołań do „na”, a z drugiej do „w”. Na szczęście różnice są tutaj marginalne. Jest jednak dość prawdopodobnym, że najwięcej źródeł wskazuje zwrot „na”.
– wyspach,
– świecie,
– mieście,
– rejonie.
Wybór jest dość trudny, jednak dla każdego fana Liverpoolu (a tych nie brakuje) – oczywisty. Właśnie w taki sposób, dzięki predykcji i AutoTokenizerowi oraz plikom wsadowym, uzyskujemy wygenerowane przez SI zdanie: Liverpool to najlepszy klub piłkarski na świecie.
W kolejnych zdaniach model będzie odwoływał się do niego, tworząc dalsze części publikacji. W modelach GPT można zdefiniować ilość wyszukań oraz podpowiedzi. Oznacza to, że zdanie mogło być dłuższe, wielokrotnie złożone, lub krótsze. Aplikacje webowe nie dają nam tutaj tak dużego pola do manewrowania, chociaż na tym tle na pewno warto docenić Rytr.me, które wypada nieco lepiej, niż WriteSonic.
Dlaczego teksty generowane przez SI wychodzą źle?
Tutaj raz jeszcze można odnieść się do ulubionych słów w branży SEO: to zależy. Tak naprawdę po drodze mogliśmy popełnić wiele błędów. Zdecydowana większość osób, które tworzą publikacje dzięki Sztucznej Inteligencji, korzysta z narzędzi webowych.
To świetne, korzystające z API GPT-3 rozwiązania, jednak minie jeszcze sporo czasu, zanim WriteSonic, Rytr, czy Jasper będą w stanie dostarczyć świetnych tekstów na każdy możliwy temat. Dlaczego? Problemem jest ograniczona baza treści w naszym ojczystym języku.
Python — niezwykle użyteczny język programowania dla wszystkich, którzy chcą trenować SI
W cenie każdej z tych usług kupujemy sobie prosty, intuicyjny interfejs, czas generowania tekstu zbliżony do minuty oraz wiele innych świetnych rozwiązań. Nie kupujemy jednak szeregu zaawansowanych funkcji oraz realnego wpływu na to, jakie dane ma w swojej bazie model.
Oznacza to, że generowane publikacje mogą być bardzo niskiej jakości na przykład ze względu na to, że próbujesz tworzyć wpisy z wąskich obszarów rynku. Na pewno łatwiej będzie stworzyć świetny wpis o modzie czy globalnie rozpoznawalnym klubie piłkarskim, niż o rotulach do szkła sprzedawanych tylko w jednym mieście w Polsce.
Moje doświadczenie pokazuje, że odpowiednio „ukierunkowany” model już dziś radzi sobie poprawnie także i z tymi trudniejszymi zagadnieniami. Jeśli jednak korzystamy tylko z narzędzi webowych, to prędzej czy później dobijemy do szklanego sufitu, którego raczej nie uda nam się przeskoczyć.
W swojej pracy korzystam z kilku narzędzi oraz dokładnie rozpisanego procesu, który w dużej mierze minimalizuje zagrożenia związane ze Sztuczną Inteligencją. Wiele wskazuje na to, że wraz z rosnącą popularnością SI, którą napędzają takie rozwiązania, jak AI21, czy dostępny publicznie model od Mety (Facebooka) – OPT-175B, kolejne mankamenty będą stopniowo eliminowane.
Jaka przyszłość czeka tokenizację w SI?
Sporo wskazuje na to, że tokenowanie wiązkowe zakorzeni się w ekosystemie SI na dłużej. To uniwersalne rozwiązanie, które — wraz ze stopniowym wzrostem mocy obliczeniowej modułu tekstowego — będzie fundamentem zdecydowanej większości usług webowych.
Osoby, które są zainteresowane samodzielnym rozwijaniem SI, na przykład do konkretnego projektu badawczego, przede wszystkim muszą skupić się na danych wsadowych. Nawet najlepszy model z najdoskonalszym systemem tokenów, nie poradzi sobie z założonymi zadaniami, jeśli nie ma jasno ustanowionych wytycznych.
Wracając do przykładu piłkarza, od którego rozpoczęliśmy ten tekst, nawet najlepszy zawodnik na świecie niewiele zdziała, jeśli nie będzie mógł liczyć na wsparcie swoich kolegów z zespołu, na najwyższej jakości sesje treningowe, przygotowanie kardio, czy błyskotliwe porady trenera i wsparcie trybun.
Tak samo jest z SI. Aby szybko otrzymać wysokiej jakości, zoptymalizowany pod wytyczne SEO tekst, potrzeba nieco wysiłku… lub skorzystania z usług fachowców, którzy już dziś świadczą takie usługi.
Autor
Krzysztof Swoboda, Senior Content Specialist w Takaoto, AI Content Designer & Editor
Komentarze:
Comments